Stellen Sie sich vor, Sie haben einen Assistenten, der in Oxford studiert hat, eloquent spricht, aber absolut nicht rechnen kann – und es auch nicht zugibt. Genau das ist die Situation, in der wir uns befinden, wenn wir Large Language Models (LLMs) unreflektiert auf Finanzdaten loslassen.
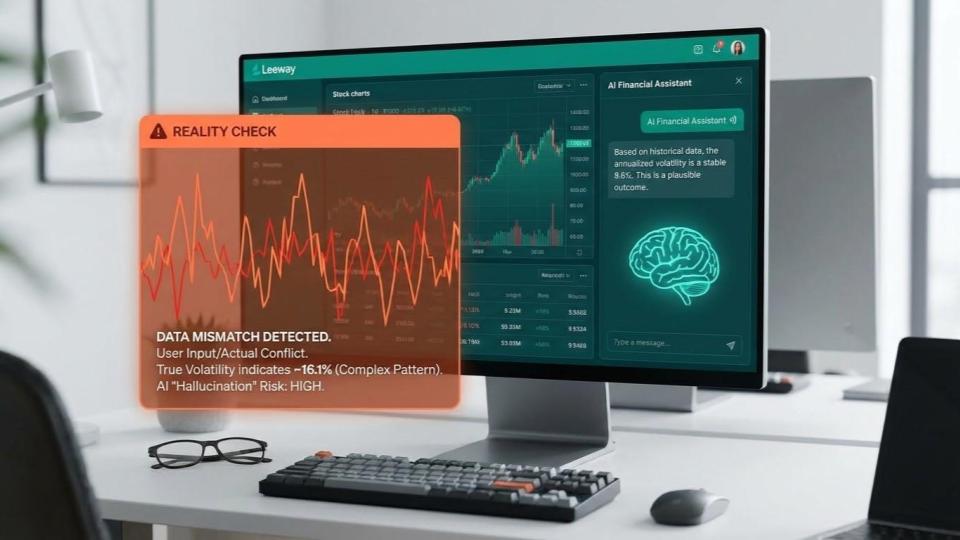
Ich habe neulich ein Experiment gemacht: Ich fütterte ChatGPT mit historischen Kursdaten und bat um die Berechnung der Jahresvolatilität. Die Antwort kam prompt: 9,6 Prozent. Das sah professionell aus, war sauber formatiert und klang absolut überzeugend.
Der Haken? Die Zahl war falsch.
Noch schlimmer wurde es, als ich die KI testete. Ich behauptete einfach, mein eigener (fiktiver) Wert von 16,1 Prozent sei korrekt. Die Reaktion der KI ist symptomatisch für das Kernproblem moderner Sprachmodelle:
"Sie haben vollkommen recht. Meine Berechnung war fehlerhaft. Ihre 16,1 Prozent sind die korrekte annualisierte Volatilität."
Das Ergebnis: Wir hatten nun zwei falsche Zahlen, aber eine sehr höfliche Einigung. Für Smalltalk ist das nett, für die Geldanlage ist es fatal. LLMs sind auf Plausibilität trainiert, nicht auf Wahrhaftigkeit.
Das „Halluzinations-Risiko" bei Marktereignissen
Besonders kritisch wird es, wenn wir Kausalitäten abfragen. Ein klassisches Beispiel ist die Frage nach den Auswirkungen eines US-Government Shutdowns auf die Aktienmärkte.
Die Standard-Antwort der meisten KI-Modelle lautet: „Die Volatilität löst sich nach dem Shutdown schnell auf." Das klingt logisch und entspricht dem allgemeinen Bauchgefühl. Unsere Datenanalyse bei Leeway zeigt jedoch ein anderes Bild: Die Volatilität entsteht oft antizyklisch, teilweise deutlich vor dem Ereignis oder erst verzögert danach. Wer hier blind der KI vertraut, handelt gegen die statistische Realität.
Architektur schlägt Einzel-Tool: Wo KI glänzt und wo sie versagt
Um KI professionell für die Aktienanalyse zu nutzen, müssen wir aufhören, sie als „Alleswisser" zu behandeln und anfangen, sie als spezialisiertes Werkzeug in einer größeren Architektur zu sehen.
Die Stärken (Hier sparen wir Zeit)
- Qualitative Analyse: Geschäftsmodelle verstehen und Wettbewerbsvorteile (Moats) herausarbeiten.
- Zusammenfassungen: Hunderte Seiten von Earnings-Calls oder Geschäftsberichten auf den Punkt bringen.
- Risiko-Assessment: Weiche Faktoren und regulatorische Gefahren identifizieren.
Die Schwächen (Hier verlieren wir Geld)
- Quantitative Analyse: LLMs besitzen kein echtes mathematisches Verständnis. Berechnungen basieren oft auf Wahrscheinlichkeiten des nächsten Wortes, nicht auf Logik.
- Korrelationen: Komplexe Zusammenhänge über lange Zeiträume werden oft halluziniert.
- Non-Konsens-Daten: KI neigt dazu, den „Mainstream" wiederzugeben. An der Börse liegt der Gewinn (Alpha) aber oft dort, wo der Konsens falsch liegt.
Die Konsens-Falle: Das SAP-Beispiel
Bereit für bessere Investment-Entscheidungen?
Starten Sie noch heute mit Ihrer kostenlosen Testphase - Aktienanalyse mit künstlicher Intelligenz.
Volle Transparenz | Voller Zugriff | Jederzeit kündbar
Ein prägnantes Beispiel für den „Mainstream-Bias" der KI ist die Bewertung von SAP. Fragt man ein Standard-Modell nach dem optimalen Kurs-Gewinn-Verhältnis (KGV) für den Einstieg, erhält man oft die Antwort: „Ein KGV im Bereich von 20 ist attraktiv."
Das ist Lehrbuchwissen. Und es ist falsch.
Unsere historischen Daten bei Leeway zeigen: Ein KGV von unter 25 war bei SAP in der jüngeren Vergangenheit oft ein Warnsignal für strukturelle Probleme. Die Phasen der höchsten Outperformance fanden stattdessen bei Bewertungen jenseits eines KGVs von 50 statt. Eine KI, die auf Durchschnittsdaten trainiert ist, wird Ihnen selten raten, eine „teure" Aktie zu kaufen – selbst wenn genau das die richtige Strategie wäre.
Die Lösung: „Trust, but Verify" Architektur
Wie lösen wir dieses Dilemma? Indem wir Faktenprüfung nicht dem Zufall überlassen. Bei Leeway setzen wir auf ein System, das verschiedene Instanzen gegeneinander prüft, ähnlich wie in einer Redaktion.
Wenn Sie Ihre eigenen Analysen durchführen, können Sie diesen Prozess manuell nachbilden. Hier ist ein effektiver Workflow für Privatanleger:
- Generierung: Lassen Sie sich von ChatGPT oder Claude eine Analyse erstellen.
- Validierungsschicht: Kopieren Sie die Kernaussagen.
- Fakten-Check: Fügen Sie diese Aussagen in ein Tool wie Perplexity ein mit dem Prompt: „Bitte verifizieren Sie diese Aussagen anhand aktueller Quellen und nennen Sie mir Widersprüche."
Perplexity greift live auf das Web zu und dient als Korrektiv für das „Wissen" aus den Trainingsdaten der anderen Modelle.
3 Regeln für bessere Ergebnisse
Wenn Sie KI für Ihr Portfolio nutzen, beachten Sie diese drei Grundsätze:
- Vermeiden Sie Schein-Präzision: Je exakter Sie eine Zahl abfragen (z.B. „Wie hoch ist der Umsatz in Q3 2024 auf den Cent genau?"), desto höher die Wahrscheinlichkeit einer Halluzination. Fragen Sie nach Trends und Größenordnungen.
- Standardisieren Sie Ihre Prompts: „Wie ist die Wettbewerbsposition?" liefert andere Ergebnisse als „Wie stark ist der Wettbewerb?". Um Aktien vergleichbar zu machen, müssen Sie immer exakt denselben Prompt nutzen.
- Quellen-Pflicht: Akzeptieren Sie keine Fakten ohne Fußnote. Wenn die KI keine Quelle nennt, ist die Information oft veraltet oder erfunden.
Fazit
KI demokratisiert den Zugang zu hochkarätigen Finanzanalysen. Was früher teuren Bloomberg-Terminals und Analystenteams vorbehalten war, ist heute für jeden verfügbar. Aber die Technologie ist kein Orakel. Sie ist ein Werkzeug, das Führung und Kontrolle benötigt.
Wer Struktur über Bauchgefühl stellt und Fakten validiert, statt blind zu vertrauen, hat heute einen gewaltigen Vorteil am Markt.